
Developing an employee directory application
The following is a report based on the design decisions that I had made during my fourth internship.
Introduction
In the summer of 2018, I worked as a Software Engineering intern at Doximity in San Francisco, California. Doximity is a medium-sized medical technology start-up and is the largest community of healthcare professionals in the country, with over 1 million verified members. Awarded by Deloitte as the Fastest Growing Company in the Bay Area in 2016 and by Apple as the Best Healthcare App, Doximity has quickly become the second most adopted piece of technology after Apple’s iPhone.
At Doximity, I had the opportunity to work on a breadth of different projects using Ruby on Rails. This included the Doximity application, Doximity Foundation, email delivery, Heaven (deployment application), Orientation (internal wiki), and more. This report will detail the engineering decisions I encountered while working on people, a brand-new employee directory application.
The Problem
Background
As Doximity continues to see tremendous growth as a company, they will also continue to outgrow existing information management systems. Without a central, single source-of-truth for employee information, this will lead to a loss of productivity which in turn results in a loss of time and money for the company. This is why employee information and knowledge management is essential to every company.
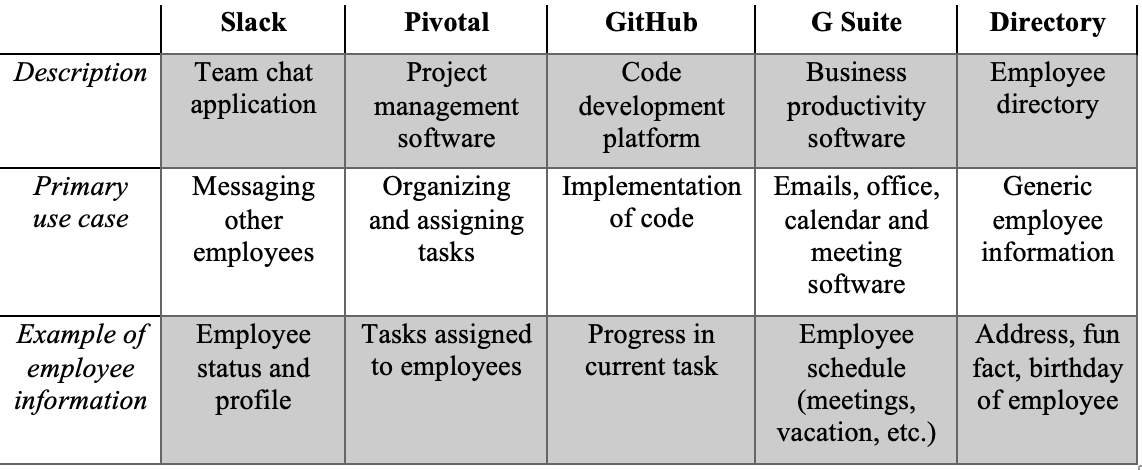
As is the case with the majority of companies, Doximity utilizes numerous other pieces of software and applications to manage different types of information. The software and tools listed in the table are not exhaustive and also only include tools used primarily by the engineering team. There is more information stored in other places such as ADP, which is an employee payroll management system. This makes it difficult to determine where it is and makes it incredibly difficult to manage, leading employees to constantly ask the same questions or be misinformed in what’s happening with the company.
An example scenario of where this confusion comes into place is if an employee wanted to figure out when “John Doe” is going to be away on his team offsite, to see if your meeting tomorrow will conflict with it. You see that he hasn’t updated his G Suite calendar to reflect his time away so you will need to determine which offsite he is going to. First, you do a search of Slack for the link to the company spreadsheet about the potential offsite. You see that each offsite is organized by company division, so you check Slack to find his profile details. In his profile details, you see that he wrote “Product Manager” and nothing else (Slack’s profile field is an unrestricted string field). You then try going to the employee directory and find that he is listed under the Ads team. You’re unsure if the Ads team is under the Product or the Growth division in the company but this information isn’t available in the employee directory. You realize that you can see which group the Ads project is under in Pivotal Tracker, so you log into Pivotal Tracker to find that the Ads team is under the Product division of the company. You then cross reference this with the spreadsheet you found initially to find that he will be away starting tomorrow, and you will need to reschedule your meeting. In the end, you ended up touching four different applications just to find out if your colleague is free tomorrow. In this contrived example, you can see how issues can arise when there is no central location for employee information.
Problem Specification
In the previous section, you saw how having many applications to handle different types of employee data can lead to confusion and chaos. The CTO of Doximity approached me about the idea of an employee directory application. The end goal of this application is to be the single source of truth for employee information and will replace most of the products in Table 2.1. We set up a meeting to flesh out the details. We discussed the high-level vision for the product and I was given autonomy beyond the outlined specification. The basic specifications are as follows:

For Pivotal activity log function, we wanted to create a service that would be able to display the last n days of activity on Pivotal Tracker (our issue tracking application).
The Solution
Class Models
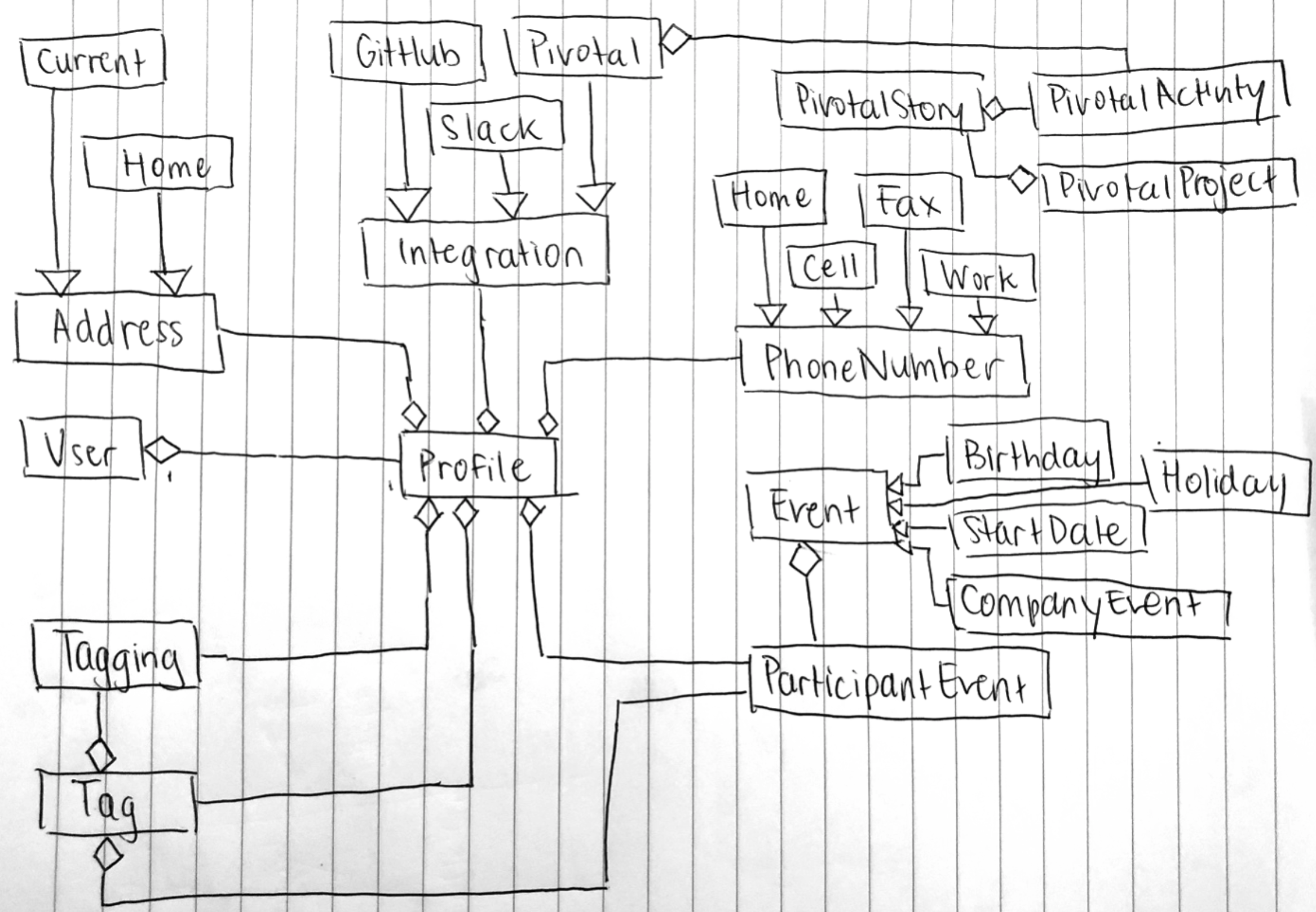
The final solution was developed using Ruby on Rails. I opted to create the following main classes:
- Address: (stores an employee’s address)
- User: (stores an employee’s email and authentication details)
- Profile: (stores basic information about an employee, e.g. name)
- Integration: (stores information about external accounts/’integrations’)
- PhoneNumber: (stores a phone number)
- Event: (stores a calendar event for participants) Participants can either be a tag (a group of users) or an individual user (using a composite design pattern)
- Tag: (a grouping of employees or other tags, e.g. for a division or a team) Using a composite design pattern
I utilized a Ruby on Rails concept known as Single Table Inheritance, where “a single table is used to reflect multiple models that inherit from a base model”[ii]. This is so that there is adequate separation between subclasses (e.g. SlackIntegration, GitHubIntegration are different classes) but they still inherit from one base class (e.g. the Integration class). This also reduces table bloat as sub and base class information are both stored in the same table. Below is a UML diagram showing the relationship between all these classes (including base and subclasses).
Pivotal Activity Log
Many design decisions came up during the implementation of the Pivotal Activity Log. These next few sections will outline the initial solution, compare and contrast the alternatives and will discuss why the final solution was chosen. References will be made to the Pivotal API, where the documentation can be found here: https://www.pivotaltracker.com/help/api/rest/v5#Endpoints.
The idea of the Pivotal Activity log is a service, where given a user and a number of days (n), it would be able to output the “Stories” that user worked on in the last n days. In Pivotal, a “User” belongs to many “Projects”, which may have many “Stories”.
Initial Implementation
Looking at all the endpoints defined in the Pivotal REST API, I determined that the “/activity/” endpoint was the best way to get the projects last worked on. This endpoint returns a list of “activities” that occurred for a given user. This includes all activity on “Stories” in “Projects” that a user belongs to. I created a function where given a user and the number of days, it would hit the endpoint and filter and order the result so that it returns a list of “Stories” last worked on.
Other than the fact that there was a lot of data is being returned and a huge amount of filtering that needed to be done, this was the best way to accomplish this “Pivotal Activity Log” feature. When testing using my account’s API token, it worked according to specification and completed within a second. What I didn’t take into consideration was that my personal account had access to a few projects, while at Doximity, there were at least 50 projects that needed to be parsed through. After we tested the initial implementation using another account which had access to all 50+ projects, we found out that the response from Pivotal cut off at about 500 results (this was not documented). This was a significant issue because, with the sheer number of employees and projects, 500 activities barely covered a few hours of activity. This is when I knew that we needed to find another alternative solution to get this information.
Alternative Solutions
Knowing that I needed to find an alternative way to obtain this information, I brainstormed the following alternatives. In the following list, a “+” indicates a PRO and a “-“ indicates a CON.
- Continue hitting the ‘/activity” endpoint, but make multiple paginated requests to satisfy the date requirement
- Only one endpoint to hit
- Already implemented so small changes
- Wasteful/not performant, lots of data returned and all that data needs to be processed
- Unpredictable in terms of how many requests needed (we don’t know how far back in time one request gives)
- Hit the ‘project/search’ endpoint instead
- No need to filter stories to look for a specific user, this means less processing of data
- New projects are automatically included in this endpoint
- This only returns in progress activity (not completed, commented on, reviewed etc.) which isn’t reflective of what an employee actually worked on
- ‘project/search’ returns projects, we are required to hit the ‘stories’ endpoint for every story in that project in order to get the person that worked on it and other details
- Hit the
project/activityendpoint - Similar to the initial implementation
- Must loop through every project (by hitting the
projectendpoint) - Still need to filter, similar to initial implementation
- Similar cons as the initial implementation such as the 500 requests limit
- Store every users’ ‘Pivotal API Key’ so we can hit the ‘my/activity’ endpoint which gives a list of activity of that user
- Seems to be the most efficient and performant
- Requires the saving of every employee’s API key which is unconventional, hard to maintain and tedious to get
- When adding a user to the application, specify which projects they work with and use solution #3 to loop through those specified projects
- More performant if data is accurate, minimal data processing
- Multiple requests still being made
- Relies on users entering correct project information, this data can easily become outdated + adds UI complexity
Enter Webhooks
Looking at all the alternative solutions, all of them either gets the information in unreliable or unconventional ways or makes multiple requests to the Pivotal API, which is impractical. Since this feature is going to be used for an activity timeline view on a profile page which loads on-demand when a user visits that page, the request must be performant and reliable. Because none of these alternative solutions satisfy this requirement, my manager suggested we look into saving the information ourselves (in the background), and surfacing it as needed. This satisfies the requirements as the data processing is done separately from render time, leaving the user experience to be quick and efficient.
Following this intuition, I noticed that the Pivotal API provided support for webhooks. A webhook is “a way for an app to provide other applications with real-time information. A webhook delivers data to other applications as it happens, meaning you get data immediately. Unlike typical APIs where you would need to poll for data very frequently in order to get it real-time. This makes webhooks much more efficient for both provider and consumer.”[iii] This works perfectly with our needs. We set-up our application to consume an event. When an activity occurs on Pivotal Tracker, it pings our application and depending on the activity type and other information, we store it in a separate table. This occurs in the background and the data gets populated in real time. This was the first time I experienced using and creating a webhook and this is clearly the best solution because it is performant and efficient. The only negative to this solution is that it takes additional storage (the storage of the activities in a table) as opposed to just hitting an endpoint and getting the data from elsewhere. These positives of this solution vastly outweigh the negatives, especially when considering all the other solutions.
Conclusions
In conclusion, a major project I had the opportunity to work on during my co-op term at Doximity was an employee directory application. Numerous engineering decisions were considered in order to determine the best solution. Notably, the implementation of the Pivotal Activity Log faced many roadblocks but using a webhook was the best solution. The final product was implemented meeting all product specification.
[i] https://www.doximity.com/about/company
[ii] http://eewang.github.io/blog/2013/03/12/how-and-when-to-use-single-table-inheritance-in-rails/